You are here
Processing Time Series in Opsview
Performance metrics
The importance of time series data in recent years has exceeded the value of information about the state of the infrastructure – hardware and software are more reliable and skilled DevOps teams don’t let problems occur by being proactive.
The game has moved to the next level – the performance of the IT systems. Telemetry is everywhere – StatsD, CollectD, Diamon, Telegraf just to name a few, supported by popular platforms such as Kibana and Grafana. And all of them have one goal – collect performance metrics and make them available to you so changes can be visualized and spotted instantly.
With Opsview 5.0, we provided the integrated Graph tab into the investigate view of monitored services and also a whole new Graph Center so you can easily combine and compare metrics.
But with the increased amount of data we collect, there is a price to pay – extra disk and system load. From the very beginning, Opsview has used the RRD - the de-facto industrial standard for storing and calculating time series data. One of the features of RRD database files is that they have a constant file size. Once created, the data is stored in the pre-created slots that are automatically rolled-up over time. However, there is a disadvantage of that architecture – once the RRD database file is created, no new metrics can be added. And due to this fact, each metric value in Opsview was stored in separate files, resulting in a great number of files on particularly complex systems. And with the sheer amount of files, the disk I/O is massive. Every update to a file has to issue several system calls, slowing down the update process.
So the problem was clear – increased load on your Opsview Orchestrator server, being locked to a particular Time Series technology and no way of improving it. That is until the arrival of Opsview 5.2!
Opsview Solution
Opsview 5.2 for Timeseries processing provides infinite scalability and is technology agnostic.
That is quite a statement, isn’t it?
Let’s start with a description of how the Time Series were processed in previous versions of Opsview:

Click image for full-size
And all of those tasks (which are very IO intensive) were executed in a single-threaded process on the Orchestrator server while it was already quite busy processing the actual results.
So the obvious solution would be to allow to move the parsing and processing from the Orchestrator server to a remote server – and that’s the role of the following packages.
Process flow overview

Click image for full-size
Opsview Timeseries
In our benchmarks, we confirmed that almost 40% of time of import_perfdatarrd is spent parsing the results, the rest is updating the RRD file (or should we say waiting for the disk). So a new parser was created and it is over 20 times faster than the previous. One problem solved!
But as you know, the RRD database does not allow the adding of past results – any timestamp older than the most recent is rejected. To allow batching the writes to the disk and to order the incoming result, we have provided another package: opsview-timeseries-enqueuer.
Opsview Timeseries Enqueuer
This very simple component has only one task – receive the parsed results, queue them for the configurable amount of time and number of requests before sending it ordered by time down the line.
As you can imagine, any process which accumulates data over time will keep on using more and more memory. That is why this component has only one sub-process that after reaching the limit, will stop accepting new requests to send the data further and once it’s done, it exits. The manager process spawns another worker and all the memory used by the previous is now released to the OS.
You have already noticed that thus far, no data has been stored anywhere yet, which moves us to the last element: opsview-timeseries-rrd.
Opsview Timeseries RRD
Finally, we have reached the actual Timeseries provider. As stated before, the RRD was used in Opsview since the very beginning and over the years, a lot of data has been accumulated in them.
Custom integration may have been created and that set the main requirement for this package – to be 100% compatible with previous versions of Opsview. Therefore, the folder structure and naming convention has been preserved, which allows for a seamless upgrade process.
The only change was how the metadata for each metric is stored - unit of measurement to be precise. In the past, it was stored in a separate uom file, which was located next to every RRD file. This has been now migrated to a SQLite3 database that helps list available metrics much faster than traversing file system.
The Timeseries RRD package provides two separate services – Updates and Queries, one handles the writes while the latter queries requests. This separation allows you to configure your system in a way that is specific to your workload. Systems with numerous graphs would definitely prefer to increase the number of dedicated workers handling those kind of requests. Configuration now also allows to specify the step size and RRA databases for newly created RRD database files.
And since the RRD is the last component in this process flow, it can be easily replaced by any other technology as long as it follows the defined protocol for writes and queries. This is what enabled us to create another provider, allowing us to store data in the InfluxDB TimeSeries Database which will be released with the next version of Opsview (although for those brave and impatient, the code in raw form is available at my Github repository).
Scalability
The last, but not least feature of the new Timeseries processing, which has been hinted before, is the ability to deploy the data across multiple servers. The way we provide this feature is by using a consistent hashing algorithm that dispatches both writes and queries to a specific server, thus all metrics of service checks of given hosts are always sent to the same server.
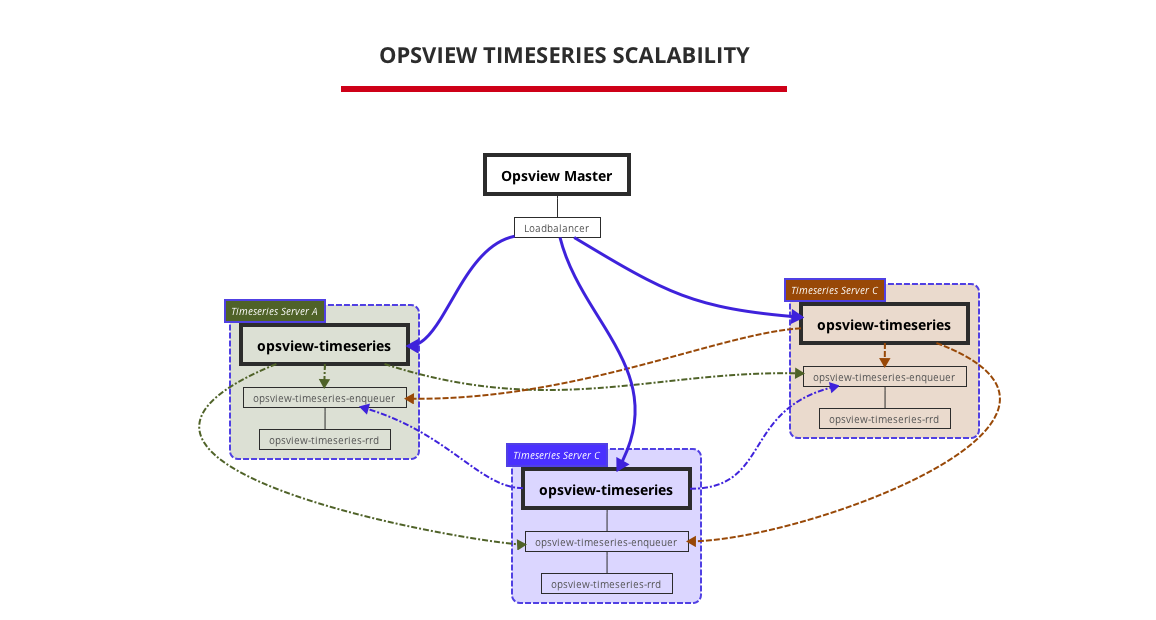
Click image for full-size
Opsview Timeseries is a stateless process, so by using a HTTP load balancer you can evenly spread the work of extracting new metrics and directing queries. Since all Opsview Timeseries workers are configured to know about other nodes, they are able to dispatch writes to Enqueuers and queries to RRD Queries on other servers. Write requests that contain multiple hosts are split and sent to all nodes in parallel. Naturally, queries follow the same logic - if a request contains multiple hsm parameters, they are dispatched to relevant servers.
Performance improvements
In our internal benchmarks, the processing of the performance data was faster by a whopping 30%. Those improvements were achieved thanks to the use of multi-processing design, which allows the utilization of available resources. And when installed on another server, the CPU and disk load of import_perfdatarrd on the orchestrator server was reduced from 100% to 0.2%. Multiple parsers can run concurrently on different CPU cores, and the same with the RRD Updaters working in parallel updating their own shards of RRDs. New flexible configuration allows fine tuning of the number of worker processes, locations and number of servers, letting our customers achieve the highest performance on the hardware that they have available.
More speed needed?
Even with the multiple servers in place, there is a certain limit of the load any disk can handle. The RRD metric files are relatively small (24kb with default settings) so another alternative is possible – store all RRD files in RAM disk. To store 100,000 metric files, only 2.4gb of RAM is needed. Although that solution carries a risk of losing data in case of power failure, that could be mitigated with a periodic rsync to disk. The middle ground would be to use SSD disks, in which performance does not degrade so heavily with concurrent writes. And now with the new architecture, you are in the control of the data.
If you need more information how to set up a scalable system, please refer to our Knowledge Center or contact our Professional Services Consultants who will be happy to assist.